日本分子疫学コンソーシアム(J-CGE)
メンデルランダム化解析を用いた日本人集団における糖代謝異常と大腸がんリスクの関連
-日本分子疫学コンソーシアム(J-CGE)からの成果報告-
日本分子疫学コンソーシアム(J-CGE:Japanese Consortium of Genetic Epidemiology studies)より、ゲノム情報を用いたメンデルランダム化(MR)解析を用いて、血中の糖代謝指標(空腹時血糖値、ヘモグロビンA1c、空腹時Cペプチド)と大腸がんリスクとの関連を分析しました。その研究成果を専門誌に発表いたしましたので紹介します(Sci Rep. 2023年4月オンライン掲載)。
研究背景・メンデルのランダム化解析について
耐糖能異常やインスリン抵抗性が、大腸がんの発がんに関与している可能性が報告されています。高血糖は、細胞内の酸化ストレスを上昇させ、がん化を誘引する可能性が指摘されています。また、高インスリン血症は、細胞増殖の促進や抗アポトーシス作用により、大腸がんのリスクが高くなるとが考えられます。しかしながら、アジア人を対象とした糖代謝異常と大腸がんのリスクを調べた大規模な疫学研究は少なく、関連がないという報告も散見されます。日本人を対象とした研究でも、糖尿病の既往歴があると大腸がんリスクが上がることが報告されています(Goto A, et al. Int J Cancer. 2015)。一方、インスリン関連指標のC-ペプチドと大腸がんリスクの関連は、男性で正の関連、女性では関連を認めませんでした(Otani T, et al. Int J Cancer. 2007)。これらの観察疫学研究では、血糖値が高い群と低い群において、大腸がんの罹患リスクを比較するにとどまり、比較する群の(血糖以外の)背景因子(例えば、社会経済状態、人種、肥満や脂質異常などその他の生活要因)が大腸がんの罹患リスクに影響を与えている可能性(=交絡[こうらく])があり、調整を行っても完全には影響を排除できませんでした。また、既存研究では知られていない未知・未観察の交絡因子も想定されることから、因果関係を言及することに限界がありました。
近年、前提条件を満たせば、交絡因子の影響を最小限にし、因果関係を推測できるMR法が注目されています。曝露に関連する一塩基多型(single nucleotide polymorphism [SNP])などの遺伝子多型は、メンデルの法則により生まれる時にランダムに選択されるため、リスクアレルを持つ群と持たない群の間の背景因子の分布は等しくなると想定されます。このことを利用して、MR法では、曝露因子と疾病との間の因果関係について推測する研究手法です。
そこで、本研究では、これまで行われてきた糖代謝に関連する形質(空腹時血糖値、ヘモグロビンA1c、空腹時Cペプチド)に関するSNPを用いて、MR解析により、遺伝的に予測される耐糖能異常と大腸リスクとの関連を検討しました。
研究方法
MR解析で使用する、糖代謝に関連するSNPとして、これまで世界から報告されているSNPの情報を集めたデータベースであるGWASカタログから網羅的にSNPを同定しました(空腹時血糖値:34SNP、ヘモグロビンA1c:43SNP、空腹時Cペプチド:17SNP)。これらのSNPのセットについて、まず、SNPと各糖代謝指標の関連の強さを推計しました。解析対象者は、J-CGEに含まれる多目的コホート研究(Japan Public Health Centre-based Prospective [JPHC] study)、東北メディカルメガバンク計画(Tohoku Medical Megabank Community-Based Cohort [TMM])、 日本多施設共同コーホート研究(Japan Multi-Institutional Collaborative Cohort [J-MICC] study)の中で、ゲノム情報と糖代謝関連指標のデータを有する参加者(ただし、すでに糖尿病の診断や治療を受けている患者は除く)のデータを用いて推定しました。解析対象者は、空腹時血糖値:17,289人、ヘモグロビンA1c:52,802人、空腹時Cペプチド:1,666人でした。本研究に用いられたSNPによって、研究参加者の空腹時血糖値のばらつきの2.48%、ヘモグロビンA1cの1.22%、空腹時Cペプチドの1.04%を説明できると推定されました。
次に、SNPと大腸がんの関連の強さについて、JPHC、J-MICC、長野大腸がん症例対照研究(NAGANO)、愛知県がんセンター病院疫学研究(Hospital-based Epidemiologic Research Program at Aichi Cancer Center [HERPACC])、およびBioBank Japan (BBJ)プロジェクトにおいて集められた大腸がんの症例と大腸がんのない対照(コントロール)のデータを用いて推定しました。解析対象者数は、症例が約8,000症例、対照が約38,000例でした。
上記の結果を用いて、2サンプルのMR解析(一つのデータセットを用いてSNP-曝露の関連を推定し、別のデータセットを用いてSNP-アウトカムの関連を推定し、それらの結果を用いて曝露とアウトカムの関連を推定する方法)を行い、各糖代謝関連指標と大腸がんの関連の強さを推定しました。
研究結果: 遺伝的に予測される血糖値・ヘモグロビンA1cと大腸がんの関連は認めませんでした。一方、統計学的に有意ではないものの、Cペプチドが増加するにつれて大腸がんのリスクが増加傾向を認めました。
図1に、空腹時血糖値を例に、SNP-血糖値の関連の強さ (x軸)、SNP-大腸がんの関連の強さ(y軸)を図示しています。図1の中に示されている直線の傾きが、2サンプルのMR解析によって最終的に推定された血糖値と大腸がんの関連の強さを意味します。MR解析には、inverse-variance weighted (IVW)法(各SNPにおける曝露のアウトカムに対する比を逆分散で重み付けして合わせることにより、全体としての曝露とアウトカムの関連の強さを求める方法)、MR-Egger法(SNPが多面的効果 [pleiotropy: 一つの遺伝子が複数の形質に影響を与えること]を持つ可能性を統計学的に考慮する方法)、weighted median法、weighted mode法、MR-PRESSO法、など様々な手法が提案されており、複数の手法を行うことで、結果の頑健性を検証しました。
IVW法による血糖値1mg/dLの増加あたり、大腸がんのオッズ比は、1.01 (95%信頼区間 0.99–1.04) 倍、ヘモグロビンA1c1%の増加あたり、大腸がんのオッズ比は、1.02 (95%信頼区間 0.60–1.73) 倍で関連を認めませんでした。また、他のweighted medianやMR-Egger法などでは、血糖値・ヘモグロビンA1cと大腸がんの間に関連を認めませんでした。
一方、空腹時Cペプチドと大腸がんのMR解析(IVW法)を行ったところ、Cペプチドの対数変換値1 (log-ng/mL)増加あたり1.47 (0.97–2.24) 倍と、統計学的に有意ではないものの正の関連を認めました(図2)。しかし、IVW法以外の手法では関連を認めませんでした。
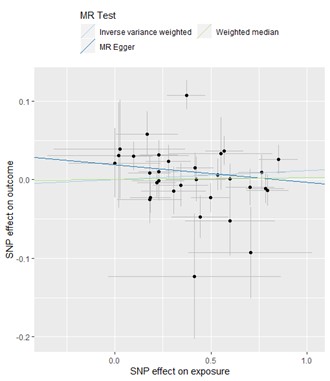
図1:血糖値と大腸がんのMR解析結果
選出した34個のSNPごとに、横軸に血糖値に対する効果量、縦軸に大腸がんに対する効果量をプロットした図です。水色(IVW法)および青色(MR-Egger法)の実線の傾きは、34のSNPの血糖値に対する効果量と大腸がんに対する効果量の比を統合した値に一致し、血糖値の大腸がんリスクに対する関連の指標であるオッズ比に換算できます。
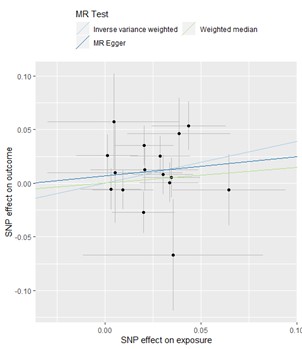
図2:Cペプチドと大腸がんのMR解析結果
選出した17個のSNPごとに、横軸にCペプチドに対する効果量、縦軸に大腸がんに対する効果量をプロットした図です。水色(IVW法)では、統計学的に有意ではないものの正の傾向を認めました(P値=0.06)。
この研究について・今後の展望
今回のMR解析により、Cペプチドが上昇すると大腸がんリスクがあがる可能性が示唆されましたが、統計学的検出力が低いために信頼区間が広く、感度分析でも支持が得られなかったことから、結果の頑健性は確認できませんでした。これまでに、欧米人を対象とした大規模なMR研究では、インスリン関連指標と大腸がんの有意な正の関連が報告されております。従って、Cペプチドに関しては、症例数を増やした検討を行うことで、大腸がんとの因果関係があることは否定できない可能性が示唆されます。一方、遺伝的に予測される血糖値、ヘモグロビンA1cと大腸がんの関連は認められませんでした。これらの結果は、既報の非アジア人を対象としたMR解析の結果と同様です。
MR解析により妥当な結果を得るためには、3つの前提条件(①SNPが糖代謝と関連していること、②SNPが糖代謝を介してのみ大腸がんの罹患に影響すること、③SNPと大腸がんの罹患との間に交絡因子が存在しないこと)を満たすことが必要であり、本研究がこれらの前提条件を満たしていたかを結論づけることには限界があります。さらに、MR解析では、非常に多くの解析対象者数が必要であることも知られており、サンプル数を増やした更なる検討で結果が異なる可能性も考えられます。以上から、エビデンス構築のためには、日本からのさらなるサンプル数を増やしたMR解析の蓄積が期待されます。