
多目的コホート研究(JPHC Study)
乳がんの遺伝的リスクスコアの開発について
―多目的コホート研究(JPHC研究)からの成果報告―
私たちは、いろいろな生活習慣と、がん・脳卒中・心筋梗塞などの病気との関係を明らかにし、日本人の生活習慣病予防と健康寿命の延伸に役立てるための研究を行っています。平成2年(1990年)と平成5年(1993年)に、岩手県二戸、秋田県横手、長野県佐久、沖縄県中部、茨城県水戸、新潟県長岡、高知県中央東、長崎県上五島、沖縄県宮古の9保健所管内(呼称は2019年現在)にお住まいだった40~69歳の方々のうち、①調査開始時のアンケート調査への回答と血液の提供にご協力下さった女性約2万2千人の方々と、②調査開始から5年後の調査で初めてアンケート調査への回答と血液の提供にご協力下さった女性約6千人の方々を対象に、ゲノムに見られる遺伝子多型(DNA配列の個人差)を可能な限り利用して、将来の乳がん発生を予測する指標となる遺伝的リスクスコアの研究開発を行った成果を、専門誌で論文発表しましたので紹介します(Breast Cancer Res Treat. 2023年2月公開)。
近年、様々な疾患を対象に、ゲノムに見られる遺伝子多型を可能な限り利用した遺伝的リスクスコアの研究開発が行われています。乳がんについては、欧米人女性を対象とした研究は数多くありますが、日本人女性を対象とした研究はこれまでありませんでした。本研究では、Breast Cancer Association Consortium(BCAC)において欧米人女性(乳がん症例122,977人と対照105,974人)を対象に行われた大規模ゲノム解析の公開データと、BioBank Japan(BBJ)において日本人女性(乳がん症例5,552人と対照89,731人)を対象に行われた大規模ゲノム解析の公開データをそれぞれ用いて、ゲノムに見られる遺伝子多型を可能な限り利用した乳がんの遺伝的リスクスコアの研究開発を行い、その妥当性を多目的コホート研究のデータで検証したうえで、どちらが日本人女性の乳がん罹患を予測するのに優れているか比較しました。
保存血液を用いた研究の方法について
本研究で対象とした多目的コホート研究の調査開始時の集団(約2万2千人)を平成21年(2009年)まで追跡したところ、263人の乳がん症例が把握されました。乳がんに罹患した女性と比べるため、対照として、8,149人を約2万2千人から無作為に選択しました。このうち、ゲノムデータが得られたのは、乳がん症例260人と乳がん既往のない対照7,845人でした。
同様に、多目的コホート研究の調査開始から5年後の集団(約6千人)を平成21年(2009年)まで追跡したところ、63人の乳がん症例が把握され、対照として、2,271人を無作為に選択しました。このうち、ゲノムデータが得られたのは、乳がん症例63人と乳がん既往のない対照2,213人でした。
本研究では、BCACおよびBBJの大規模公開データから、乳がんの遺伝的リスクスコアを開発しました。そして、多目的コホート研究の調査開始から5年後の集団で遺伝的リスクスコアの選択を、調査開始時の集団で選択された遺伝的リスクスコアの検証を行いました。
遺伝的リスクスコアの開発
遺伝子多型と乳がん罹患との関連の確からしさを表す指標であるP値(0に近づくほど偶然見られた関連である可能性が低い)と遺伝子多型同士の関連の強さを表す指標であるR2(1に近づくほど関連が強い)を段階的に変化させることで、遺伝的リスクスコアに含める遺伝子多型の数を調整しながら、BCACとBBJの大規模公開データをもとに、それぞれ24通りの遺伝的リスクスコアを開発しました。
遺伝的リスクスコアの選択
開発した遺伝的リスクスコアを多目的コホート研究の調査開始から5年後の集団に当てはめ、乳がん罹患を予測する性能を、ハレルのC統計量(Harrell’s C-statistic)と呼ばれる指標(1に近づくほど予測性能が高い)で評価しました。図1に示すように、BCACの大規模公開データを用いた場合は、P値= 5×10−4でR2 = 0.8の条件で開発した遺伝的リスクスコアのC統計量が0.627 で最大となり、BBJの大規模公開データを用いた場合は、P値= 0.05でR2 = 0.2の条件で開発した遺伝的リスクスコアのC統計量が0.592 で最大となりました。
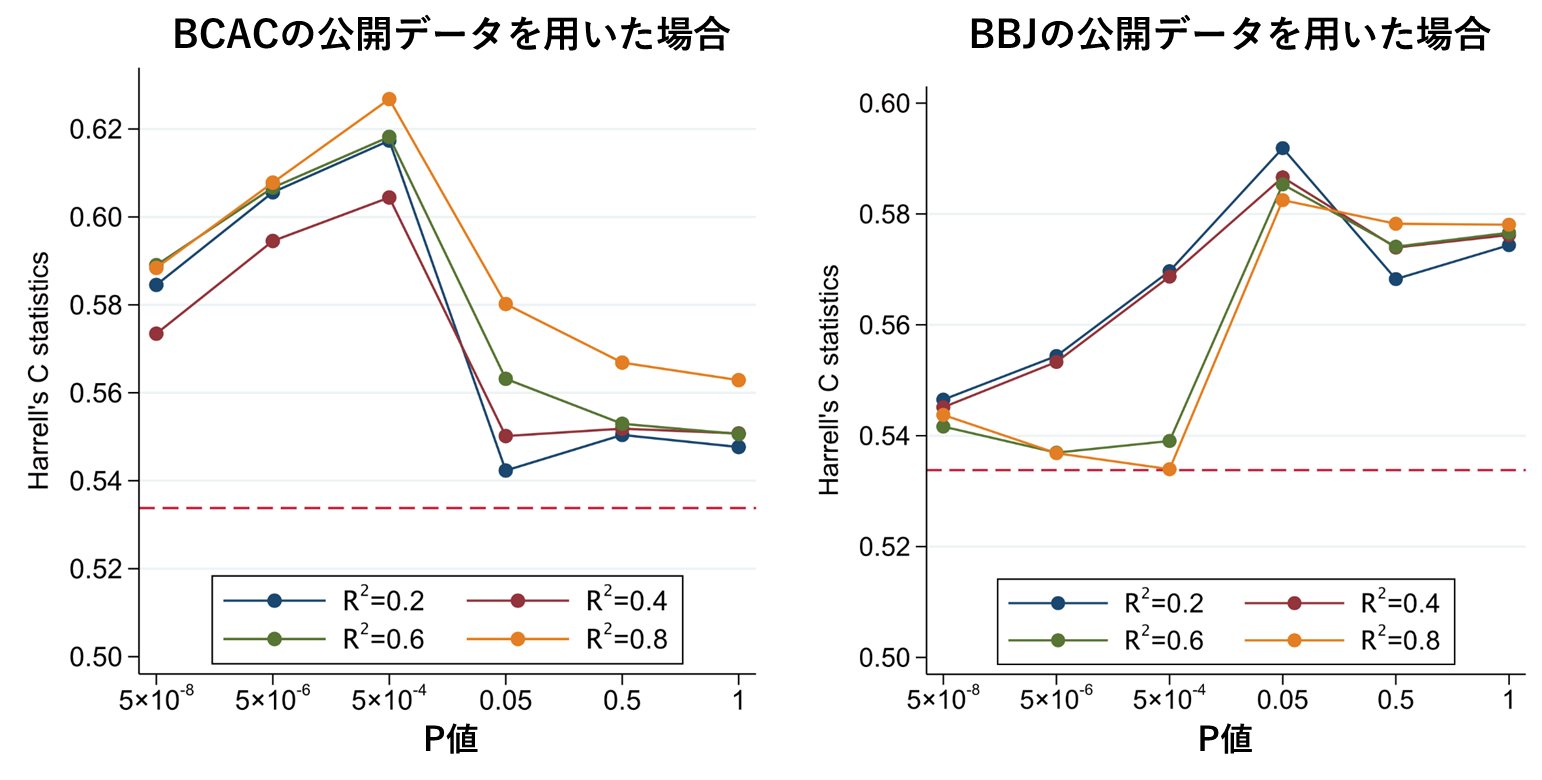
図. BCACおよびBBJの大規模公開データから開発した遺伝的リスクスコアの予測性能
選択された遺伝的リスクスコアの検証
上記で、C統計量をもとに選択された遺伝的リスクスコアが、多目的コホート研究の調査開始から5年後の集団で示した予測性能を、他の集団では示さない可能性があるため、遺伝的リスクスコアの検証では別の集団(多目的コホート研究の調査開始時の集団)に当てはめて、C統計量を再評価しました。BCACの大規模公開データから開発・選択された遺伝的リスクスコアのC統計量は0.627から0.586に大きく低下しましたが、BBJの大規模公開データから開発・選択された遺伝的リスクスコアのC統計量は0.592から0.598と大きく変化せず、BCACの大規模公開データから開発・選択された遺伝的リスクスコアより高いC統計量を示しました。
まとめ
本研究において、欧米人女性を対象とした大規模ゲノム解析の大規模公開データ(BCAC)と日本人女性を対象とした大規模ゲノム解析の大規模公開データ(BBJ)をそれぞれ用いて、ゲノムに見られる遺伝子多型を可能な限り利用しながら、将来の乳がん発生を予測する指標となる遺伝的リスクスコアの研究開発を行ったところ、日本人女性の大規模公開データをもとに開発した遺伝的リスクスコアの方が、より良い予測性能を示す可能性が示されました。この予測性能は、比較的よく知られている欧米人の遺伝的リスクスコアを検証集団(多目的コホート研究の調査開始時の集団)に当てはめて得られた値(ハレルのC統計量で0.582)より、わずかに優れていました。人種が異なると、遺伝子多型が見られるゲノム上の位置や頻度が異なるため、遺伝的リスクスコアを開発するもととなる大規模ゲノム解析が行われた集団の特性と、遺伝的リスクスコアを適応する集団の特性が一致している方が、遺伝的リスクスコアの予測性能がより良くなると考えられます。
本研究によって研究開発された遺伝的リスクスコアで、日本人女性が生まれつき持っている乳がんリスクを高い人と低い人に層別化できる可能性があります。実用化までは更なる研究が必要ですが、遺伝的に乳がんリスクが高いと予想された人には、検診を積極的に推奨することで、乳がん予防に役立つツールとして利用できる可能性があります。
本研究では、乳がん罹患に強く影響する稀な遺伝子変異は考慮されておらず、研究の限界点と言えます。今後、遺伝性乳癌卵巣癌症候群のような、より遺伝的リスクの高い方々にも適応できる遺伝的リスクスコアの研究開発を進めていく必要があります。
研究用にご提供いただいた血液を用いた研究の実施にあたっては、具体的な研究計画を国立がん研究センターの倫理審査委員会に提出し、ヒトゲノム・遺伝子解析研究に関する倫理指針について審査を受けてから開始します。今回の研究もこの手順を踏んだ後に実施いたしました。国立がん研究センターにおける研究倫理審査については、公式ホームページをご参照ください。
多目的コホート研究では、ホームページに多層的オミックス技術を用いる研究計画のご案内や遺伝子情報に関する詳細も掲載しています。